2024-01-22: I’ve updated this to work with Playwright 1.41.
Last week started like every other week, meaning half a dozen projects were broken by half a dozen incompatible dependency updates. There were the usual suspects like Lexical but most noticeable was Playwright.
Playwright had been more-or-less behaving up until 1.39, but something in 1.40 was causing the WebKit tests to intermittently fail, a lot.
Nothing in the commit
log
stood out except a few opaque feat(webkit): roll to r1926-type commits
and there didn’t seem to be a pattern to the failures other than having to do
with text input and focus—which is basically all our tests.
So I decided to do the grown-up thing and collect some data.
Trying to be lazy
I asked ChatGPT for the simplest possible way to analyze the test data which politely suggested I use Lambda to ingest data to DynamoDB or RDS coupled with QuickSight, Angular and Flask and possibly Athena, ELK stack, DataDog and Grafana.
And this point I’m pretty sure ChatGPT was trolling me so instead I was forced to use my own two fingers to query a search engine the old-fashioned way. Fortunately that turned up the amazing Currents which was everything I was looking for and more.
I spent a couple of hours setting it up “just right” and was thoroughly impressed to see it live stream the test results. Very nice work.
The trouble came when I stepped into the office the next morning and got a mail saying that while I was sleeping I’d hit the limit of the free tier. I was about to to pull out my wallet until I calculated that for this little project with its pitiful E2E test suite of only about 280 tests running on three browser engines, it would cost about $500 per month to send all the test results to Currents, or about 50 times as much as it costs to actually run the tests 😬
I suppose I could have tried to negotiate but I don’t think this AI was about to give me a 98% price reduction.
I backed out all my Currents setup but not all was lost. In the process of setting it up, I’d been introduced to the magic of Playwright test sharding.
Normally sharding splits your test runs up into roughly-equally sized buckets that can be run in parallel but I wondered if you could split them up by browser instead. It turns out you can and it has a lot of advantages, but there are a few tricks needed to get it to work.
Sharding by browser
Firstly, in our GitHub Actions workflow we set up a matrix based on the different browsers we’re targeting:
e2e:
runs-on: ubuntu-latest
name: E2E tests
timeout-minutes: 20
strategy:
fail-fast: false
matrix:
browser: [chromium, firefox, webkit]
include:
- maxFailures: 10
- maxFailures: 40
browser: webkit
This setup allows us to tweak the parameters used for each browser such as the number of allowed failures or the number of workers, for example.
Then we need to install Playwright but we can be a bit clever and only install the dependencies needed for the browser we are running which will speed up CI time even further.
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
cache: yarn
node-version: 18
- name: Install
run: yarn install
# Playwright cache:
#
# Based on https://github.com/microsoft/playwright/issues/7249#issuecomment-1154603556
#
# Figures out the version of Playwright that's installed.
#
# The result is stored in steps.playwright-version.outputs.version
- name: Get installed Playwright version
id: playwright-version
run: echo "version=$(cat yarn.lock | grep "^\"@playwright\/test" --after-context 1 | tail -n 1 | sed 's/\s*version "\([0-9.]\+\)"/\1/')" >> $GITHUB_OUTPUT
# Attempt to restore the correct Playwright browser binaries based on the
# currently installed version of Playwright (the browser binary versions
# may change with Playwright versions).
#
# Note: Playwright's cache directory is hard coded because that's what it
# says to do in the docs. There doesn't appear to be a command that prints
# it out for us.
- uses: actions/cache@v3
id: playwright-cache
with:
path: '~/.cache/ms-playwright'
key: '${{ runner.os }}-playwright-${{ matrix.browser }}-${{ steps.playwright-version.outputs.version }}'
# As a fallback, if the Playwright version has changed, try use the
# most recently cached version for this browser. There's a good
# chance that the browser binary version hasn't been updated, so
# Playwright can skip installing that in the next step.
#
# Note: When falling back to an old cache, `cache-hit` (used below)
# will be `false`. This allows us to restore the potentially out of
# date cache, but still let Playwright decide if it needs to download
# new binaries or not.
restore-keys: |
${{ runner.os }}-playwright-${{ matrix.browser }}-
- name: Install Playwright with dependencies
if: steps.playwright-cache.outputs.cache-hit != 'true'
run: npx playwright install --with-deps ${{ matrix.browser }}
- name: Install Playwright's dependencies
if: steps.playwright-cache.outputs.cache-hit == 'true'
run: npx playwright install-deps ${{ matrix.browser }}
Finally we run the tests.
- name: Run E2E tests
run: yarn playwright test --project=${{ matrix.browser }} --max-failures ${{ matrix.maxFailures }} --workers 2
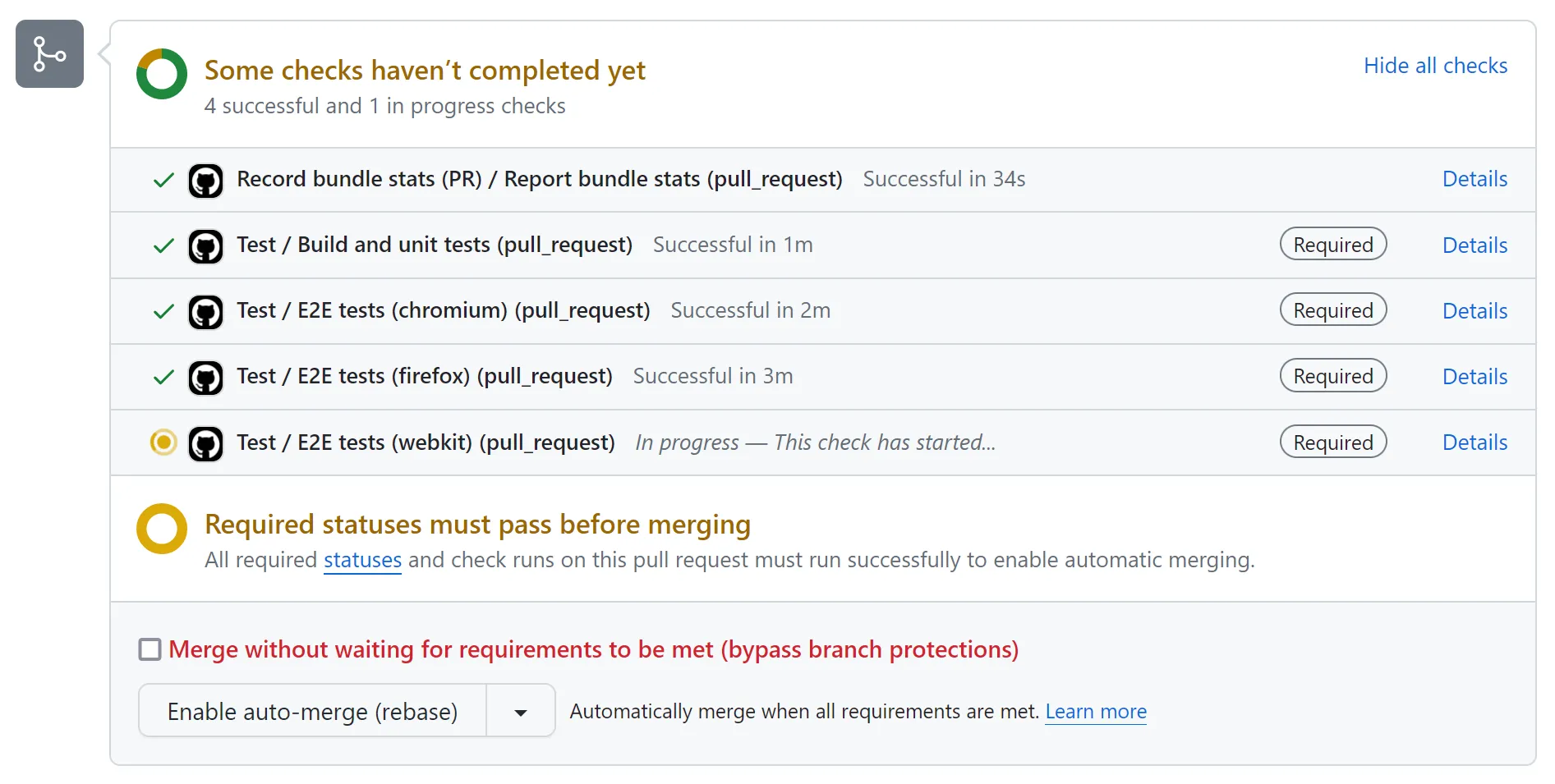
With all that, our browsers run as separate tasks which means:
- CI run setup time is reduced since we only install the required dependencies for one browser.
- You can adjust the run parameters separately by browser.
- You can potentially run different browsers on different hardware.
- You can tell at a glance who you’re waiting on.
Here’s how it looks:
Merging reports
One of the problems with sharding is that all your test results are sharded too. Playwright, however, very conveniently provides a utility for re-uniting them.
The first step is to configure your tests to use the blob reporter.
So in playwright.config.ts you might set your reporter to something like:
reporter: process.env.CI ? [['github'], ['blob']] : 'list',
However, if we do that all the reports would have the same name and they’d
clobber each other when we tried to merge them.
When you shard using the regular --shard 1/3 approach Playwright
adjusts the name of the reports for you, but when you shard by browser you’re
on your own.
Prior to Playwright 1.41 this was as simple as setting the
PWTEST_BLOB_REPORT_NAME environment variable but 1.40 added a fileName
option to the blob
reporter which is a
little more cumbersome to use.
First we need to stick our browser name in an environment variable. For example:
- name: Run E2E tests
run: yarn playwright test --project=${{ matrix.browser }} --max-failures ${{ matrix.maxFailures }} --workers 2
+ env:
+ PWTEST_BOT_NAME: ${{ matrix.browser }}
Then, when we set up the reporter, we can pass that into the fileName:
reporter: process.env.CI
? [
['github'],
[
'blob',
{
fileName: process.env.PWTEST_BOT_NAME
? `report-${process.env.PWTEST_BOT_NAME}.zip`
: undefined,
},
],
]
: 'list',
Finally, once all shards are done, we upload the artifacts and merge them together:
- name: Upload any failure artifacts
uses: actions/upload-artifact@v4
if: always()
with:
# upload-artifact@v4 no longer permits overlapping artifact names so
# we need to make the name unique
name: blob-report-${{ matrix.browser }}
path: blob-report
retention-days: 1
upload-reports:
if: always()
name: Upload Playwright reports
needs: [e2e]
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
cache: yarn
node-version: 18
- name: Install
run: yarn install
- name: Download blob reports from GitHub Actions Artifacts
uses: actions/download-artifact@v3
with:
path: all-blob-reports
# download-artifact@v4 will download each artifact to a separate directory
# based on the artifact name but merge-reports won't look into
# subdirectories so we need to flatten the hierarchy.
- name: Move reports into the same folder
run: mv all-blob-reports/blob-report-*/*.zip all-blob-reports/
- name: Merge into HTML Report
run: npx playwright merge-reports --reporter html ./all-blob-reports
- name: Upload HTML report
uses: actions/upload-artifact@v4
with:
name: html-report-${{ github.run_attempt }}
path: playwright-report
retention-days: 14
The final report looks something like this:
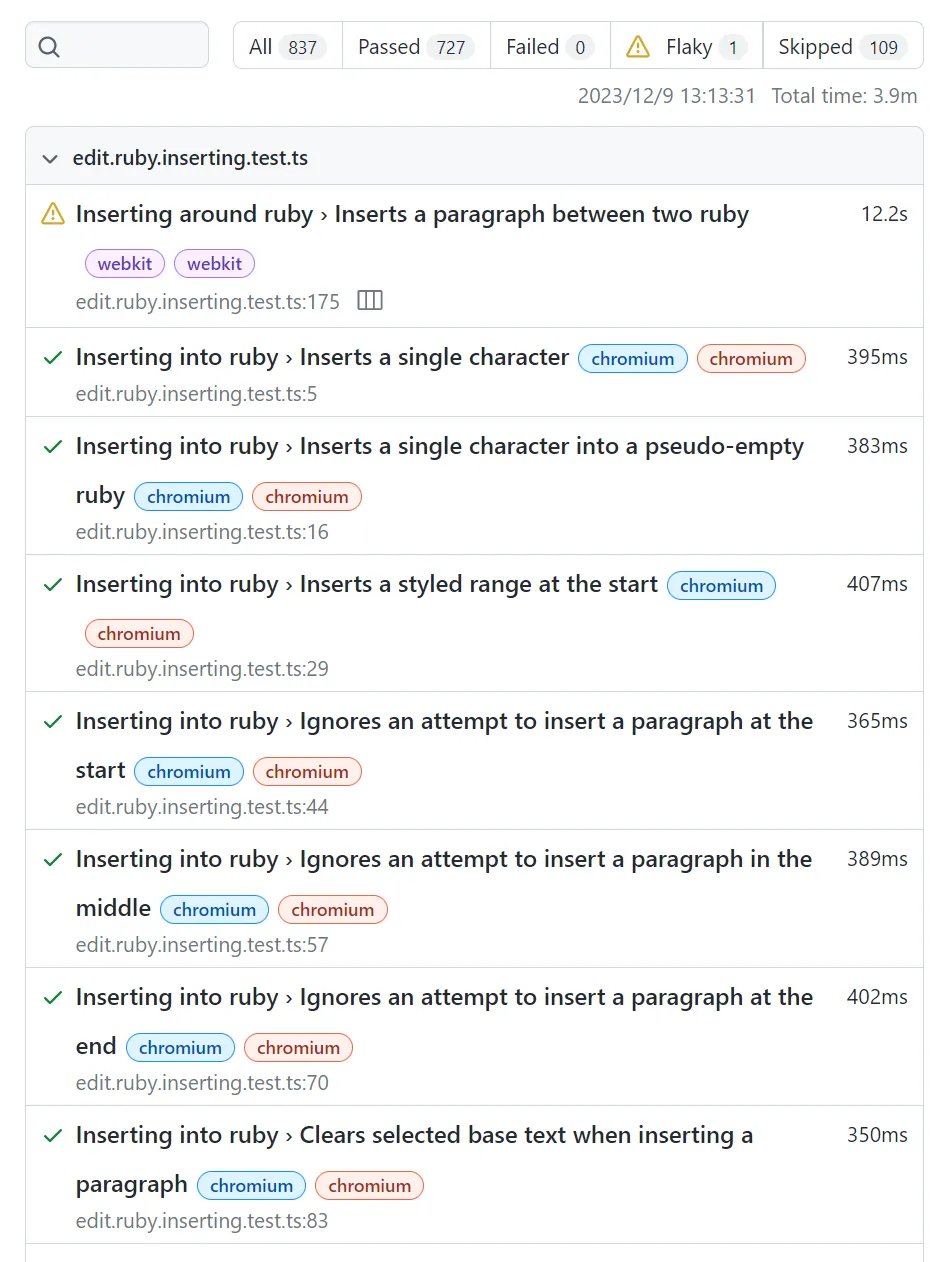
I suspect the reason it shows “webkit” and “chromium” twice next to each test run is because it tags the results both by shard name and the engine (“project” in Playwright terms) which happen to be the same in our case.
Back to debugging WebKit
I still haven’t worked out what’s going on with WebKit. I’ve disabled half the tests from running on WebKit and it still takes four times as long and fails ten times as often as Chrome and Firefox but working that out is a subject for another blog or two.